If you like a Python Tool for crowdsourcing Learning. Please access our CrowdwiseKit tool on GitHub.
CEKA has been downloaded by researchers from over 40 countries. (details)
CEKA is a software package written in Java that focuses on the analysis of data obtained from multiple workers via crowdsourcing. Specifically, CEKA works to uncover patterns among the labels with which the workers annotate the data. CEKA incorporates the data mining software WEKA (Waikato Environment for Knowledge Analysis) into its functionality, making for a convenient, simplistic interface.
First of all, CEKA provides easy-to-use methods to load data. Once the data is loaded, CEKA can utilize powerful methods to perform consensus (label integration) on crowdsourced data. CEKA provides to the user such consensus methods as KOS (Karger, Oh, and Shah) and DS (Dawid and Skene), both named after their creators. Since crowdsourcing (a human process) will inevitably lead to some errors in data annotation, CEKA also provides some noise filters and noise correction methods, which can be utilized to lessen the impact of the errors. A few noise filters CEKA includes are Classification Filter and Multiple Partitioning Filter.
CEKA supports the entire knowledge discovery procedure including analysis, inference and model learning. It has a hierarchical architecture. In the data layer, CEKA is able to read an arff(x) file defined by WEKA, which contains features of instances for subsequent model building. In the inference and learning layer, it provides a large number of inference algorithms and a batch of noise handling algorithms. The core classes in this layer are derived from related classes in WEKA. In the application layer, CEKA provides a lot of utilities such as calculating performance evaluation metrics (i.e., accuracy, recall, precision, F source, AUC, M-AUC), manipulating data (i.e., shuffling, splitting and combining data), etc.
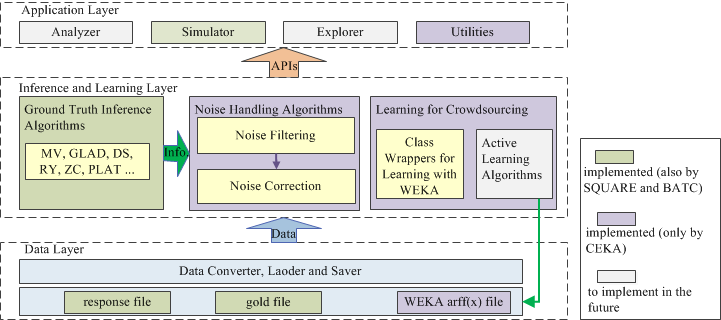
Click the respective links to visit SQUARE and BATC.
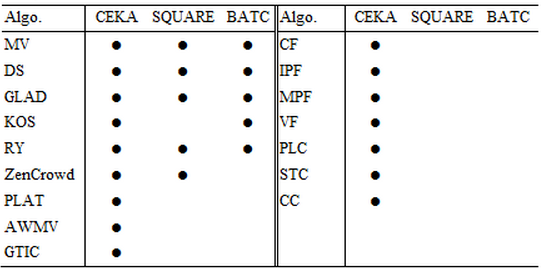
CEKA currently provides a large number of agnostic inference algorithms, such as majority voting (MV), adaptive weighted majority voting (AWMV), the Dawid & Skene's algorithm (DS), GLAD, KOS, etc., and a batch of noise handling algorithms, such as classification filtering (CF), iterative partition filtering (IPF), multiple partition filtering (MPF), voting filtering (VF), polishing label correction (PLC), etc.
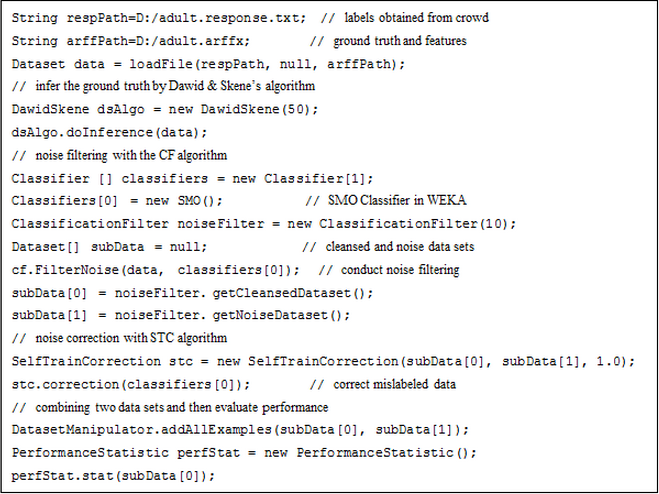
The following example demonstrates a simple experiment including the ground truth inference, noise correction and performance evaluation. In this sample code, like DS, all inference algorithms provide a uniform interface function doInference which assigns every instance an integrated label. The class Dataset is completely compatible with the class Instances in WEKA which can be directly accepted by a WEKA classifier as its parameter to train a model. Simply as the code shows, the statistical information of the performance will be obtained when the class PerformanceStatistic is applied to a Dataset object with the ground truth provided.
For much more information on CEKA and how to use it, please view the user guide.
Click here to download the latest stable release of CEKA.
Alternatively, you may visit the sourceforge.net project summary page for CEKA (where you can also download CEKA) here.